2007年4月5日
荆轲及其他人
新近传的一出剧本《荆轲传》,加上合意太爷那边借题发挥的“迷信”故事,推荐一读。
以前也了解荆轲刺秦的故事,但是像里面提到的田光自刎一事,是头次看到。这种自杀,两种解读,一曰忠义,二曰愚昧。这种在古时时不时就上演的轰轰烈烈的自杀以明心迹,在今人看来,是封建愚忠的教化结果。
早先看《赵氏孤儿》,就有这种疑问,假使组麂没有触槐而死,而是跟着赵盾到金殿上和屠岸贾对质,恐怕屠岸贾就不会那么张狂了吧,还扬言“既有人前去行刺,哪有刺客触槐而死之理?”还有那个守宫的韩厥,他要不自刎,屠岸贾追来询问,编一篇瞎话哄过,也许屠岸贾就不会对孤儿的事儿起疑心了。包括《铡美案》里的韩琪,没杀秦香莲,不能回复驸马,大可以跟着秦香莲去见包公,指证陈世美,所谓“杀妻灭子”,也就有了干板人证了。
这一干人,在并非完全进退两难的境地,都选择了自我了断……
其实看似明朗的退路,在他们的思想里,其实是死路一条。让他们背叛自己的主子,甚至再和主子作对,也许他们的行为是正义的,但他们是要背上叛主骂名的。于是乎,他们也就没有了退路。
《荆轲传》里的田光也是如此,主上随便一句言语,就刺激了这位先生的敏感神经,于是只能以死表明心迹。封建的礼数,有时候是挺吓人的。
至于荆轲,其实挺失败的,还搭进一堆人的性命。剧本结尾处有一段被抓后骂始皇帝外带“敲牙割舌”(京剧中经典刑法),大约就是为了显示荆轲的勇武,毕竟如果按《史记》上的内容走,刺杀失败,被抓后直接给消灭了,戏结束的就太仓促了。
尽管把荆轲和其他自刎的义士放在一起扯了半天,但小豆子始终觉得,他和那些人差着一些档次。
拾慧:王君安北大见面会
拾慧:父亲是个好「孟良」
2007年3月29日
星期三
看了一下日历,发现连续一个多月,都没有在星期三写过 Blog,很在情理之中的事情。
一般来说,星期三是去图书馆的日子,上上个星期借的书要去还,还要借本周要借的书,然后周而复始,每周都有借有还、再借不难地重复着。去图书馆路上花掉的时间,应该就是平常写 Blog 的时间长度吧,至少差不多。
大部分书都是和戏有关的,也有一些闲书。书多了有时也看不过来,两周期限到了,没看多少,又得还。但守着一堆书确是很好的事情,需要什么,随手查来。当然,没有电子版的搜索起来方便,这也是要把剧本数据化的一个理由吧。
没事儿了,絮叨絮叨,就为破开这个星期三不写 Blog 的规律 
拾慧:从京剧伶人杨宝忠被冻饿死说起
京剧盗版盘
友人从上海休假回来,大约知道小豆子好戏,特地带了三张京剧 DVD,这是小豆子见到的比较专业的一份京剧盗版盘了。
这套名为“中国京剧表演艺术家·周信芳”的盘,让小豆子最先想到的是周先生的那几部艺术片,因为上面还写着“名家大师,原人演绎”。而实际上呢,是周先生那些音配像的集合,而且从质量上看大概就是 VCD 的那些转过来的,凑到 DVD 盘上。每出戏的片头只留剧目名,没有录音年代、配像演员等,亦没有片尾的字幕。
DVD 的标题菜单做的还算精良,每出戏的剧名加上片断都很清楚。光盘本身也不差,甚至比小豆子以前买的一些正版曲艺的资料还有好。从盘的后面看,尚有一圈“中国京剧表演艺术家周信芳”的反光字样,只不过是反的,是让你从正面去读的,而你从正面看却因为正面有图案而遮住了。
小豆子不晓得这样的音配像浓缩盘是否很流行,只是每次自己回国的时候,都买天津出的那原版的 VCD。一来没有见到有这样的盗版,二来,戏曲出版物,还是以不鼓励盗版的为好。不过毕竟,一个对京剧一窍不通的朋友,并没有嘱咐让带什么回来,能够给捎来三张京剧的盘,已经很欣慰了,不可能再指望人家分清正版盗版来。
发现头一张盘的卷标很哏儿,不知道做盗版的人,当时在想什么。不可言传,有截图为证:
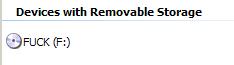
光盘卷标
嗯…… 
一些小事儿
这些天一直在忙业务上的事儿,也就耽误了“业务”上的事儿。
毕竟每天朝九晚五的现实工作还是主业,而这些天这个工作时间又因事情多而扩展到晚上,虽然是在家干活儿,但无疑影响了戏——这不是正经事儿的业务。于是,这几天几个网站都没有更新。
今天给京剧剧目考略更新了几个据网友提交的资料整理的剧目介绍,这是自网站开放测试以来第一次据提交的内容更新。这个网站一直默默地呆在那儿,来串门的人少,更不要说关注的了。试运行已经半年,准备再花半年的时间,一来提高人气,二来在修饰一些细节,三来后台管理的程序要更新,提高生产力,然后就可以算是脱离测试期,正式下水了。
最近虽说主业上忙,但忙里偷闲,把老舍先生的《猫城记》看完了,有些沉重,推荐一读。很久没有看这么神奇的寓言故事了。